前言
上篇文章 介绍了插件的前端部分,这篇我们来介绍怎么对提取出来的内容进行翻译。生活在 ChatGPT 的时代,当然要好好利用一下这个工具了,所以本文就用它来进行翻译了。
接入 ChatGPT
本文没有采取官方 API_KEY 的方式,而是需要用户先自行登录 ChatGPT,然后利用跨站请求会自动携带 cookie 这一特性先请求 openai 的 /api/auth/session 接口获取 accessToken,然后使用其来发起对话,核心代码如下所示:
1 | async sendMessage(params: { |
由于 conversation 返回的 Content-Type 是 text/event-stream 类型的,所以本文使用了 eventsource-parser 来进行解析:
1 | async parseSSEResponse(resp: Response, onMessage: (message: string) => void) { |
注意,这里的 async *streamAsyncIterable 是个 AsyncGenerator,感兴趣的可以自行学习。
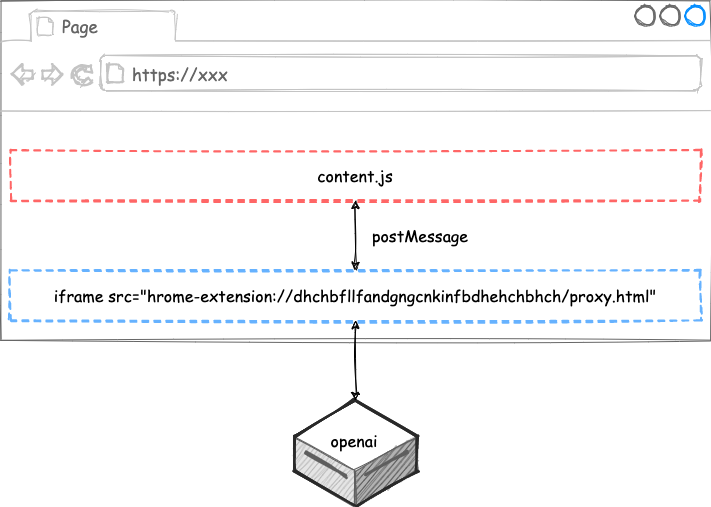
但是,直接在 content.js 中运行上述代码是会跨域的,因为我们插件的 content.js 其实是运行在其他网页之中,那么怎么解决呢?答案就是代理。
首先,从插件的页面发起请求到 openai 是不会跨域的,所谓插件的页面就是类似于这样的页面:chrome-extension://dhchbfllfandgngcnkinfbdhehchbhch/index.html,其中 // 后面那一串是插件的唯一 id。所以,我们可以在网页中插入一个不可见的 iframe 来作为 Proxy,通过 postMessage 让其跟 content.js 互相进行通信:
好了,搞定了 ChatGPT 的接入,接下来就是翻译了。
翻译
上篇文章中我们已经提取出了待翻译的内容,并且按照段落组织好了,所以,接下来的任务就轻松了。我们先把每个段落的待翻译文本收集成一个数组:
1 | paragraphs.forEach( |
接下来我们写一个这样的 Prompt,发送给 ChatGPT:
1 | `I will give you a JSON array, please translate each item from ${from} to ${to} and |
其中,文本中 from 和 to 分别是原文语言和目标语言。然后,我们把得到的翻译结果解析出来,并显示到页面上即可:
1 | paragraphs.forEach(({translationEl}, index) => { |
总结
我们通过两篇文章介绍了如何实现一个并行翻译的 Chrome 插件,实测发现,翻译的速度有点慢,即使我们做了只翻译视口中的内容的优化。但其实还有优化空间,比如我们现在是等所有的文本都翻译好以后再一起返回结果,但 openai 的返回是流式的,我们也可以流式地进行处理。之前在编译原理之手写一门解释型语言中介绍的状态机貌似可以派上用场,即我们可以通过一个状态机来不停地匹配翻译后的文本 token,这个后面有空再优化了。最后,欢迎关注公众号“前端游”。